人工智能大模型高速发展,对算力的需求飙升,不仅是数值增长,更对稳定性、精准性和持续供给能力有了严苛要求。在此背景下,高效、稳定且可大规模扩展的AI计算集群,已成为推动前沿AI研发突破的核心基础设施。应行业需求,2023年底,国产GPU公司摩尔线程首次推出专为大模型训练打造的夸娥(KUAE)智算集群,为国产AI算力添力。经过一年半的迭代升级,尤其搭载最新一代智算卡MTT S5000后,该集群在硬件算力、软硬件协同及系统效率上均实现跨越式进步。
最新数据显示,基于S5000的千卡智算集群,其计算效率超过同等规模国外同代系GPU训练集群。这意味着,国产GPU智算平台在支撑前沿AI训练的关键能力上,已能与国际领先水平看齐。

夸娥(KUAE)智算集群:为前沿大模型训练而生
夸娥(KUAE)智算集群是以全功能GPU为硬件核心,软硬一体化、完整的系统级算力解决方案,其核心构成包括作为核心硬件基础设施的全功能 GPU 计算集群、用于集群管理的夸娥集群管理平台(KUAE Platform),以及支持大模型开发的夸娥大模型平台(KUAE ModelStudio),旨在为大规模 GPU 算力的建设和运营管理提供系统级支持。
作为AI智算集群,夸娥可扩展至万卡规模,单集群可部署超过1000个计算节点,每个节点集成8颗摩尔线程自研OAM模组化形态的GPU,并通过优化的3D全互联拓扑实现了极低的通信延迟,能为像DeepSeek这样的千亿参数大模型预训练提供稳定且高效的算力支撑。
在技术层面,夸娥(KUAE)智算集群的突破点在于解决大模型训练的核心挑战,包括高效计算与通信、突破显存与效率瓶颈、超长稳训练保障。此外,还能为MoE混合专家模型、多模态模型等前沿复杂 AI 架构提供理想的训练环境,以此支持复杂架构的训练。
全栈AI布局:芯片到集群的完整拼图
夸娥(KUAE)智算集群的成功运行,充分彰显了摩尔线程在AI算力领域从芯片到系统的全栈布局能力。这一能力不仅体现在其覆盖多样化需求的产品矩阵中,更依托关键技术突破与生态构建形成了完整竞争力。
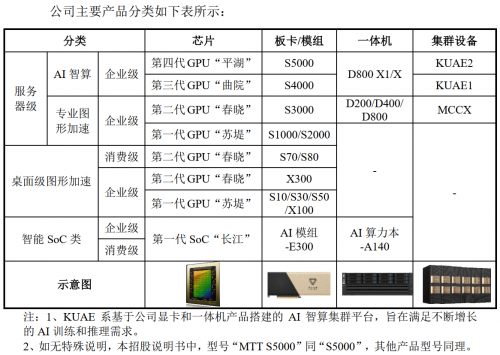
在产品线方面,摩尔线程已推出系列核心产品:包括支持FP8精度的最新智算卡MTT S5000、训推一体全功能智算卡MTT S4000、支持千卡互联的第一代超大规模智算融合中心产品KUAE1,以及支持万卡互联的第二代方案KUAE2。目前,这些产品已实际交付多个智算中心,广泛应用于大模型训练、推理及科学计算等场景。
在关键技术方面,作为少数掌握FP8计算精度的国产GPUㄏ商,在该领域与全球领先的英伟达保持技术同步。其全功能GPU可高效满足DeepSeek V3/R1等大模型的FP8原生预训练计算需求,具备显著的产业应用潜力。
经过四年发展,摩尔线程成功构建起全栈自研的MUSA软件生态,这一生态体系不仅能与国际主流GPU生态实现无缝兼容,更借助自动化迁移工具Musify,实现了新模型的即时“Day0”级迁移,极大降低用户切换算力平台的门槛。
凭借全栈自研能力和开放的“KUAE+MUSA”生态,摩尔线程正成为中国GPU产业发展的中坚力量。面向未来,摩尔线程将持续深耕AI算力领域,以技术创新为引擎,不断迭代升级智算硬件产品与软件生态体系,在推动自身技术与产品突破的同时,助力国产GPU在全球AI算力竞争格局中稳步前行。(国产GPU:https://www.mthreads.com/)





